Last time I was working with Elasticsearch, I thought that writing a post about refresh api usage on bulk operations may help newcomers. But then I realized that it is better to explain elasticsearch api basics and refresh api first.
In this post I will talk about Elasticsearch basics.
Elasticsearch, with the words of itself, is a distributed, RESTful search and analytics engine. It is built on Apache Lucene. Apache Lucene creates and manages inverted indexes and Elasticsearch gets its power from searching indexes instead of searching texts. Inverted indexes keep a list of all unique words in a document and for each word, list of the documents that contains this word.
Elasticsearch is near real time search platform. After you add some documents to an index, it will be ready for search in seconds. (1 second in default).
To understand Elasticsearch structure well, we can compare the terms with RDMS terms.
| ES |
RDMS |
| Index |
Table |
| Document |
Row |
| Field |
Column |
At the past, It is told that ES Type is similar to RDMS Table and ES Index is similar to RDMS Database. But Types are removed in new versions of Elasticsearch.
Personally, I am adding prefixes to Index Names and these prefixes provide me a logical database.
New records in Elasticsearch is called Document and storing new document is called Indexing. Indexes contains one or more Documents and Documents contains one or more Fields.
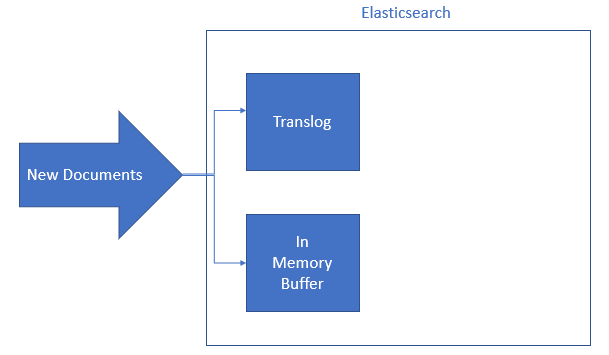
When you insert a new document, it is firstly added to a memory buffer and Translog. At this level, new documents are not be able to search and it is just in memory. Translog (transaction log) helps elasticsearch to recover datas that has not committed yet and exists in memory in case of crash.
The reason that why Lucene commit is not used instead of Translog is Lucene commits are heavy operations and doing Lucene commit after every document insert/delete/update will decrease performance of the app drastically. To prevent this performance decrease, first data written to Translog and fsynced to Translog with some interval or after requests. These can be changed by settings.
Translog file datas are committed with some intervals to Lucene. So to big translog files are prevented and new translog is created. Commit to Lucene operation can be done with Flush API, we will talk about it in the next post.
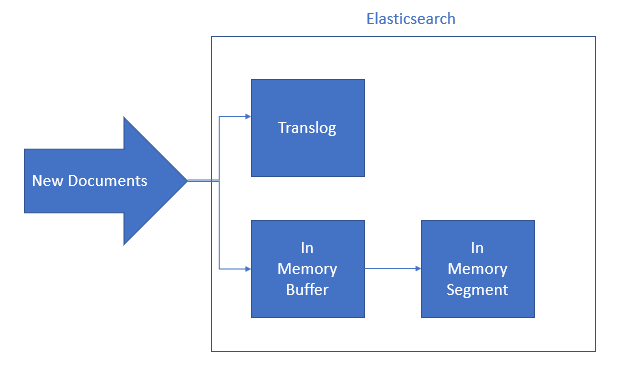
After the first refresh request to Index (We will talk about fresh api in the next post too), documents that is in Memory Buffer,copied to a new segment in memory again. From now on, documents are searchable.
We will talk about persistence problem, refresh api and flush api in the next post.
Let’s continue with Elasticsearch architecture a bit more.
Elasticsearch can be scaled horizontally by adding new nodes to clusters. A cluster is group of servers that keep your data. It organizes your indexing and searching operations between nodes.
As we talked just before, a node is a server as a part of cluster and it joins the searching and indexing operations. You can add any number of nodes to a cluster.
Shards
An elasticsearch index is comprised of shards. A shard is a lucene index and it cannot be breakable. If you have only one shard in your elasticsearch index and your data is too much for your server capacity, It will cause problems. Shards can be hosted different nodes so you can separate your elastic search indexes to different nodes. Pros of shards:
- Split content into different nodes
- Scale horizontally
- Improve performance
Segments
Shards contain segments that are actualy data structures with inverted indexes. Datas are kept in segments. Every indexing operation creates new segments. These segments are searched sequentially. Therefore, If there are too many segments it will decrease the performence. To prevent this, elasticsearch merges similar size segments into bigger segments. This merge operation is done by some cpu and i/o operations that effects bulk indexing operation’s performance. To prevent this, it is a good advice disabling merges before bulk operations.
Segments are immutable, so if you update a document, it is marked as deleted and new document is created. Documents that is marked as deleted, is deleted completely by merge operations.
Replicas
Replicas are copy of primary shards but still shards. They are not stored in the same nodes with primary shards. So, they provide that if some server failures or connection problems occur, elasticsearch continues to response requests over replicas.
In first time bulk indexing, setting number of replicas to 0 will improve performance but you may loose your data if some server failure occurs while indexing. After the bulk operation completed. You can set the number of replicas whatever you want.
In this post, I tried to make a introduction Elasticsearch world, If you have any comment or questions, please share below. I will talk about refresh api and flush api in my next post.
Thanks 🙂